- 2.1.1 기본 자료형을 바라보는 관점
- 2.1.2 Modern C++
- 2.1.3 다양한 데이터 초기화 방법
2.1.1 기본 자료형을 바라보는 관점
C++에서 다루는 기본 자료형은 많이 있지만 모든 자료형을 완벽하게 외우려고 하는 것보다 사용하면서 체화하는게 프로그래밍 공부에서 덜 스트레스 받는 방법일 것이다. 나도 여전히 실무에서 기본적인 것에 대해 검색을 해보곤 한다. 기본 자료형의 종류를 암기하는 것보다 중요한 것은 자료형을 여러가지 종류로 두고 쓰는 이유가 바로 메모리 할당 크기에 있다는 점이다. 또한 자료형의 이름이 같을지라도 컴파일러마다 자료형의 메모리 크기는 다를 수 있으니 주의하자.
메모리 크기를 다룰 때 사용하는 것이 바로 바이트(byte)와 비트(bit)이다. 1 byte = 8 bit임을 기억해두자!
#include <iostream>
#include <bitset>
int main()
{
using namespace std;
int i = -1;
char a = 'H';
cout << (uintptr_t)static_cast<void*>(&i) << endl;
cout << (uintptr_t)static_cast<void*>(&a) << endl;
return 0;
}Integer types 중에서 가장 대표적인 int 자료형은 4 bytes의 크기를 가지고 있다.
문자를 저장하는 char 자료형은 character type이기도 하고 Integer type이기도 하다. char 자료형에 'A'로 초기화하는 것과 65로 초기화하는 것은 'A'로 초기화하는 효과를 가져온다. 즉, 문자이면서 숫자가 된다. 이렇게 말하게 되는 이유가 네트워크 영역에서는 char 자료형을 통해 1 byte 단위의 숫자를 다루기 때문이다.
#include <iostream>
#include <bitset>
int main()
{
using namespace std;
signed int i1 = -1;
unsigned int ui1 = 1;
unsigned ui2 = 2;
// Floating-point types
float f1 = 1.0f; // 4 bytes
double d1 = 1.0; // 8 bytes
long double ld1 = 1.0;
return 0;
}자료형 앞에 signed 혹은 unsigned를 붙여서 쓸 수 있다. 부호도 취급하는 자료형인지 아닌지에 따라 각각 사용하게 되는데, 특수한 상황에서는 연산 속도마저 차이가 날 수 있다. 일반적인 자료형을 선언할 때는 signed가 붙어 있다고 생각을 하면 된다.
Float-point types(부동소수점 타입)는 우리가 익히 알고 있는 실수를 표현하기 위해 존재한다. float, double, long double이 있는데, 과학 계산을 사용하지 않는 경우에는 대부분 float 자료형으로 사용한다. 마찬가지로 메모리 크기의 차이가 있다는 점을 항상 생각해두자! 과학 계산에서 double 자료형을 쓰는 이유는 정확도를 위해서 쓰는 것으로 보면 된다. 사용하는 메모리의 크기가 클수록 더 낮은 소수점 계산까지 정확해진다. 하지만 과학 계산에서도 소수점 아래 열번째 자리를 넘어가는 수에 대해서는 truncation error 때문에 신뢰하지 않는 편이다.
2.1.2 Modern C++
조금 생소할 수도 있는 표현 중에 하나가 바로 자료형 위치에 auto를 두는 것이다.

auto를 사용하면 컴파일 단계에서 컴파일러가 해당 변수를 알아서 알맞은 자료형으로 바꿔준다. 예시를 간단하게 두었지만 auto를 사용하여 r-value에 상수가 아닌 것을 넣어 변수를 만들어낼 수 있으니 참고하자!
2.1.3 다양한 데이터 초기화 방법
C++에서는 변수 초기화하는 방법이 3가지가 있다.
int a1 = 123;
int a2(314);
int a3{ 123 };우리가 흔히 사용하는 초기화 방법인 첫번째 방법을 copy initialization이라고 부른다. 위의 예시에서 만약 r-value에 int가 아닌 부동소수점 변수를 둘 경우 자동으로 타입 캐스팅을 한다.
두번째 예시의 초기화는 direct initialization이며 객체 지향 프로그래밍을 할 때 많이 사용한다. 앞선 예시와 마찬가지로 컴파일러가 자동으로 타입 캐스팅 해준다.
마지막 초기화는 uniform initialization이며 이 또한 객체 지향 프로그래밍 때 많이 사용한다. 최근 권장하는 초기화 방법이라고 하며 앞선 예시들보다 조금 더 엄격하다. 만약 잘못된 r-value를 넣어주면 컴파일 단계에서 에러를 출력한다.
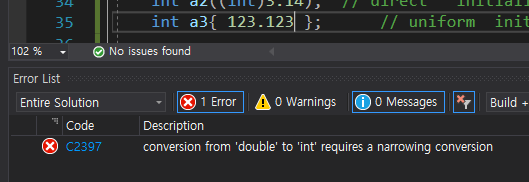
C2397 conversion from 'double' to 'int' requires a narrowing conversion이라는 말과 함께 컴파일러가 에러를 보여준다.
프로그램을 만들 때 언제나 휴먼 에러를 생각해야하기 때문에 오해의 소지가 될 법한 방식의 코딩은 피해야 한다.

위처럼 작성하면 마치 k와 l도 123으로 초기화될 것 같아 보이지만 실제로는 그렇게 동작하지 않는다.
예전 코드 작성 방법 중에 하나가 사용할 모든 변수를 프로그램 가장 앞에 모두 선언하는 방식인데, 요즘은 사용하는 곳에서 선언하고 쓰는 방식을 채택하니 참고해두는 것이 좋다. 쓰는 곳에서 선언하는 방식으로 구현해야 리팩토링할 때 편하고 다루기 쉬워진다.
'Programming Language > C++' 카테고리의 다른 글
| Section 2.3. void (0) | 2021.10.12 |
|---|---|
| Section 2.2. 정수형 (0) | 2021.10.11 |
| Section 1.10. 전처리기(Preprocessor) (0) | 2021.09.28 |
| Section 1.9. 네임스페이스 (0) | 2021.09.27 |
| Section 1.8. 중복 정의를 막는 헤더 가드와 링킹 에러 (0) | 2021.09.26 |