흔히 void라고 말하는 무치형 타입은 함수에서 반환값이 없거나 매개변수가 없을 경우 사용하게 된다. 하지만 매개변수가 없는 함수의 경우 void를 굳이 기입하지 않아도 되며, 기입하는 관습은 옛 관습이니 굳이 지키지 않아도 된다. 실무에서 그 방식으로 작성한다면 따르도록 하자.
// 매개변수 void 넣는 것은 옛날 방식
void my_function(void)
{
}
int main()
{
//void는 메모리를 차지하지 않기 떄문에 선언할 수 없다.
//void my_void;
int i = 123;
float f = 123.456f;
void* my_void;
// 데이터 타입이 다르고 사이즈가 달라도 해당 데이터의 주소를 표현하는 데이터의 크기는 동일하다.
my_void = (void*)&i;
my_void = (void*)&f;
return 0;
}
void는 메모리를 차지하지 않기 때문에 선언할 수 없다. 하지만 포인터로는 활용이 가능한데, 데이터 타입이 다르고 사이즈가 달라도 데이터에 대한 주소를 표현하는 데이터의 크기는 언제나 동일하므로 가능하다. 추후 포인터에서 다루게 되면 더 자세히 포스팅하도록 하겠다.
코드에서는 4가지에 대해서 작성되어 있지만 char 또한 정수형으로 취급한다. 네트워크 계열을 다루는 사람들은 char 자료형을 1 byte 정수 자료형으로 사용한다. 그 외 정수 자료형은 short, int, long, long long이 있으며, int 자료형과 long 자료형은 같은 크기의 메모리를 소비한다. 메모리를 많이 사용할수록 더 넓은 범위의 수를 다룰 수 있게 된다.
수를 표현할 때 부호(sign)을 표현하기 위해 1 bit를 사용한다. 양수는 0으로 표현하며 음수는 1로 나타낸다. 자료형 앞에 unsigned 키워드를 추가하면 부호를 표현하기 위한 bit마저도 수를 표현하기 위해 사용하게 된다. 이때 음수는 표현할 수 없게 되니 주의하자. 또한 정수형끼리 나누기를 수행해서 소수점이 나오게 되고 그 수를 정수형에 저장하게 되면 소수점 아래의 수는 버림이 된다.
2.2.2 limits 헤더를 이용한 정수형 한계치 확인
limits 헤더를 이용하면 자료형의 수치적 한계치를 확인할 수 있다. 앞의 코드를 통해 short 자료형은 2 bytes(16 bits)임을 알 수 있다. 하나의 bit를 부호로 사용하면 총 15 bits를 수를 표현하는 메모리로 사용할 수 있다.
절대값으로 보면 양수가 음수보다 1이 작은 것을 알 수 있다. 부족한 부분은 0을 표현하기 위해 사용이 된다.
2.2.3 overflow
앞에서 언급하였듯이 메모리의 크기에 따라 표현할 수 있는 수의 한계치가 존재한다. 만약 해당 한계치를 뛰어넘는 수를 저장하면 어떻게 될까?
#include <iostream>
int main()
{
using namespace std;
short s = 32767;
cout << "short max : " << s << endl;
s = s + 1; // 32768
cout << "short max + 1 (overflow) : " << s << endl;
s = -32768;
cout << "short min : " << s << endl;
s = s - 1; // -32769
cout << "short min - 1 (overflow) : " << s << endl;
unsigned int iii = -1;
cout << iii << endl; // overflow
return 0;
}
short 자료형의 최대값은 32767이다. 32767을 저장하고 1을 더하게 되면 32768이 아닌 -32768이 되면서 최소값이 나온다. 이처럼 한계치를 뛰어넘어서 수의 법칙과는 다르게 결과값을 가지는 것을 overflow라고 한다. short 자료형의 최소값에 -1을 할 경우 최대값인 32767을 결과값으로 가진다.
2.2.4 고정 너비 정수(Fixed-width integers)
C++ 11부터는 어떤 플랫폼이던지 고정 너비 정수를 쓸 수 있도록 설정하는 방법이 생겼다. #include <cstdint>를 통해 설정하는 것이 원칙이지만 iostream을 include할 경우 별도로 include할 필요가 없다.
C++에서 다루는 기본 자료형은 많이 있지만 모든 자료형을 완벽하게 외우려고 하는 것보다 사용하면서 체화하는게 프로그래밍 공부에서 덜 스트레스 받는 방법일 것이다. 나도 여전히 실무에서 기본적인 것에 대해 검색을 해보곤 한다. 기본 자료형의 종류를 암기하는 것보다 중요한 것은 자료형을 여러가지 종류로 두고 쓰는 이유가 바로 메모리 할당 크기에 있다는 점이다. 또한 자료형의 이름이 같을지라도 컴파일러마다 자료형의 메모리 크기는 다를 수 있으니 주의하자.
메모리 크기를 다룰 때 사용하는 것이 바로 바이트(byte)와 비트(bit)이다. 1 byte = 8 bit임을 기억해두자!
#include <iostream>
#include <bitset>
int main()
{
using namespace std;
int i = -1;
char a = 'H';
cout << (uintptr_t)static_cast<void*>(&i) << endl;
cout << (uintptr_t)static_cast<void*>(&a) << endl;
return 0;
}
Integer types 중에서 가장 대표적인 int 자료형은 4 bytes의 크기를 가지고 있다.
문자를 저장하는 char 자료형은 character type이기도 하고 Integer type이기도 하다. char 자료형에 'A'로 초기화하는 것과 65로 초기화하는 것은 'A'로 초기화하는 효과를 가져온다. 즉, 문자이면서 숫자가 된다. 이렇게 말하게 되는 이유가 네트워크 영역에서는 char 자료형을 통해 1 byte 단위의 숫자를 다루기 때문이다.
#include <iostream>
#include <bitset>
int main()
{
using namespace std;
signed int i1 = -1;
unsigned int ui1 = 1;
unsigned ui2 = 2;
// Floating-point types
float f1 = 1.0f; // 4 bytes
double d1 = 1.0; // 8 bytes
long double ld1 = 1.0;
return 0;
}
자료형 앞에 signed 혹은 unsigned를 붙여서 쓸 수 있다. 부호도 취급하는 자료형인지 아닌지에 따라 각각 사용하게 되는데, 특수한 상황에서는 연산 속도마저 차이가 날 수 있다. 일반적인 자료형을 선언할 때는 signed가 붙어 있다고 생각을 하면 된다.
Float-point types(부동소수점 타입)는 우리가 익히 알고 있는 실수를 표현하기 위해 존재한다. float, double, long double이 있는데, 과학 계산을 사용하지 않는 경우에는 대부분 float 자료형으로 사용한다. 마찬가지로 메모리 크기의 차이가 있다는 점을 항상 생각해두자! 과학 계산에서 double 자료형을 쓰는 이유는 정확도를 위해서 쓰는 것으로 보면 된다. 사용하는 메모리의 크기가 클수록 더 낮은 소수점 계산까지 정확해진다. 하지만 과학 계산에서도 소수점 아래 열번째 자리를 넘어가는 수에 대해서는 truncation error 때문에 신뢰하지 않는 편이다.
2.1.2 Modern C++
조금 생소할 수도 있는 표현 중에 하나가 바로 자료형 위치에 auto를 두는 것이다.
auto
auto를 사용하면 컴파일 단계에서 컴파일러가 해당 변수를 알아서 알맞은 자료형으로 바꿔준다. 예시를 간단하게 두었지만 auto를 사용하여 r-value에 상수가 아닌 것을 넣어 변수를 만들어낼 수 있으니 참고하자!
2.1.3 다양한 데이터 초기화 방법
C++에서는 변수 초기화하는 방법이 3가지가 있다.
int a1 = 123;
int a2(314);
int a3{ 123 };
우리가 흔히 사용하는 초기화 방법인 첫번째 방법을 copy initialization이라고 부른다. 위의 예시에서 만약 r-value에 int가 아닌 부동소수점 변수를 둘 경우 자동으로 타입 캐스팅을 한다.
두번째 예시의 초기화는 direct initialization이며 객체 지향 프로그래밍을 할 때 많이 사용한다. 앞선 예시와 마찬가지로 컴파일러가 자동으로 타입 캐스팅 해준다.
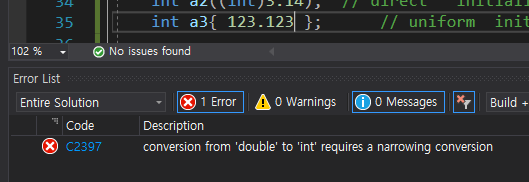
마지막 초기화는 uniform initialization이며 이 또한 객체 지향 프로그래밍 때 많이 사용한다. 최근 권장하는 초기화 방법이라고 하며 앞선 예시들보다 조금 더 엄격하다. 만약 잘못된 r-value를 넣어주면 컴파일 단계에서 에러를 출력한다.
C2397
C2397 conversion from 'double' to 'int' requires a narrowing conversion이라는 말과 함께 컴파일러가 에러를 보여준다.
프로그램을 만들 때 언제나 휴먼 에러를 생각해야하기 때문에 오해의 소지가 될 법한 방식의 코딩은 피해야 한다.
초기화
위처럼 작성하면 마치 k와 l도 123으로 초기화될 것 같아 보이지만 실제로는 그렇게 동작하지 않는다.
예전 코드 작성 방법 중에 하나가 사용할 모든 변수를 프로그램 가장 앞에 모두 선언하는 방식인데, 요즘은 사용하는 곳에서 선언하고 쓰는 방식을 채택하니 참고해두는 것이 좋다. 쓰는 곳에서 선언하는 방식으로 구현해야 리팩토링할 때 편하고 다루기 쉬워진다.
#include 전처리기를 사용하면 프로그램에 필요한 라이브러리를 끌어다가 쓸 수 있다. 가장 처음 쓰게 되는 라이브러리는 아마도 #include <iostream>인 것 같다.
#include <iostream>
using namespace std;
#define MY_NUMBER 333
#define MAX(a, b) (((a)>(b)) ? (a) : (b))
#include <algorithm>
#define LIKE_APPLE
#define을 통해 코드를 좀더 깔끔하게 작성할 수 있다. 매크로(marco)라는 명칭으로도 부르는 이 전처리기는 코드 내에 해당 매크로가 존재하는 경우 정의한 데이터로 컴파일 단계에서 교체를 해준다. 이를 통해 과거에는 많은 사람들이 max 함수를 만들어서 쓰곤 했는데, 지나친 괄호를 작성해야 올바르게 동작하기 떄문에 요즘에는 쓰질 않는다. 처음에는 공부하는 차원에서 해볼 수 있지만 max 함수 자체는 algorithm 라이브러리에 존재하니 끌어다가 쓰면 되겠다.
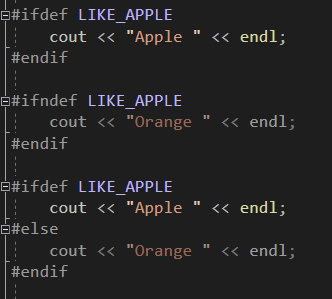
#define을 통해 교체하는 작업을 하지 않는 경우가 있는데, 바로 데이터를 작성하지 않고서 #define NAME만으로 작성된 매크로이다. 이전에도 사용하긴 했지만 #ifdef를 활용하여 코드를 작성할 때 사용하게 된다. 또한 해당 매크로는 작성된 파일 내에서만 영향력을 가지며, 그 영역을 벗어나서 동작하는 함수가 있다면 매크로가 없는 것으로 간주되니 주의하자. 이 부분은 뒤에 예시로 한번 보도록 하겠다!
먼저 작성된 코드와 함께 붙여서 쓰면 되는 코드이다. #ifdef LIKE_APPLE는 LIKE_APPLE이 정의되어 있다면 #endif까지 동작하게 해주는 전처리기이다. #ifndef는 반대로 정의되어 있지 않은 경우에 동작하게 된다. 위처럼 ifdef와 ifndef로 분할해서 만들수도 있지만, ifdef와 else를 활용하여 작성할 수도 있다. 둘 다 똑같이 작동하게 될 것이다.
앞에서 LIKE_APPLE을 정의했으니 Apple이 출력되도록 코드가 작동할 것이다. 실제 화면을 보면 Orange 파트의 코드는 희미하게 표기가 된다.
LIKE_APPLE이 정의된 경우
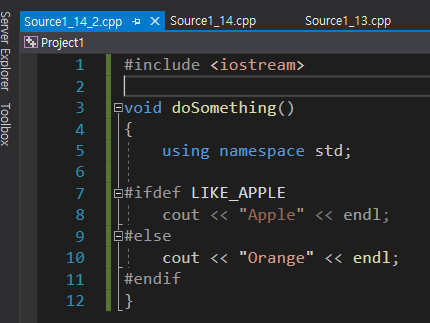
doSomething 함수는 다음과 같다.
doSomething
다른 파일에 작성된 함수이고 전방 선언을 통해 가져오도록 한다. 여기서는 Orange가 출력 될 것으로 보이는데, 앞의 코드들을 합치면 이미 LIKE_APPLE이 정의되어 있으니 doSomething도 Apple을 출력해야 할 것 같다는 생각이 든다.
result
실제 결과를 보면 doSomething에 의해 Orange가 출력되었다. doSomething 함수를 호출하는 곳에는 LIKE_APPLE이 정의되어 있어서 Apple을 출력시켰지만 doSomething 함수를 실행하기 위해 건너가는 파일에는 정의가 되어 있지 않아서 Orange가 출력된다. 이처럼 매크로의 정의는 해당 파일에만 한정되어 있으니 주의해야하며, 만약 Apple을 출력시키고 싶다면 해당 매크로를 또 작성하거나 매크로가 작성된 파일을 include로 끌어오면 되겠다.